Quell’imbroglione di Mendel
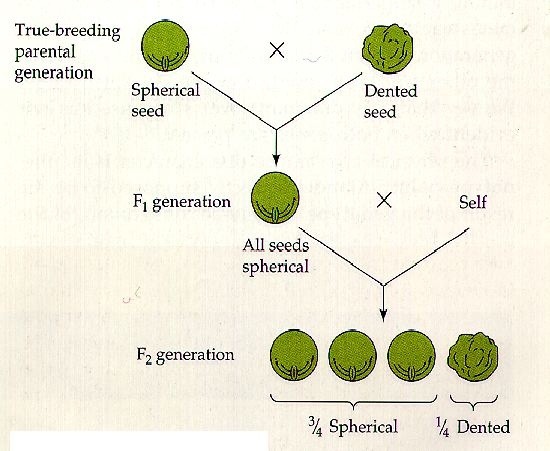
Non tutti sanno che il geniale frate Gregor Mendel, per divenire quello che noi ora riteniamo il padre della genetica, imbrogliò. Viste le conoscenze e gli strumenti a disposizione del naturalista in quella lontana epoca storica, si ritiene sia impossibile, o comunque alquanto improbabile, che con così pochi dati da prendere in considerazione, i risultati rispecchiassero alla perfezione la sua teoria.
Ma non concentriamoci su come arrivò alle sue leggi, bensì su come quest’ultime sono e che cosa comportano.
Ecco una dettagliata spiegazione di come si svolse il lavoro del frate agostiniano.
Le mutazioni geniche

Per mutazione genica si intende quella variazione, anche minima, che avviene nella struttura molecolare di un gene e che può riguardare un solo nucleotide, come anche più nucleotidi, della catena di DNA, come ad esempio la sostituzione di una purina o di una pirimidina con un’altra base azotata (per es.: come avviene nell’anemia falciforme si ha la sostituzione della timina con l’adenina). Una volta avvenuta questa mutazione nella struttura molecolare del materiale genico, essa si riproduce a ogni replicazione del DNA e cioè diventa ereditaria; soltanto un altro cambiamento potrà produrre una nuova mutazione che potrebbe anche consistere in un ritorno alla struttura originale.
Sono, quindi, le mutazioni che alterano un singolo gene e dunque le più “piccole” che si possono avere. In quanto tali non sono visibili attraverso analisi al microscopio (tranne alcuni casi estremi), ma possono essere riscontrate solo tramite analisi genetiche. Le mutazioni geniche portano alla formazione di nuove forme geniche, ovvero di nuovi alleli, detti appunto alleli mutanti. In quanto tali questi sono rari nella popolazione e si differenziano dagli alleli più diffusi detti invece tipi selvatici. Bisogna però far distinzione anche tra alleli mutanti e morfi. I morfi sono infatti due o più alleli di uno stesso gene con frequenza superiore all’1% (polimorfismo). Alla luce di questo ne deriva che il concetto di mutazione non è assoluto: un gene potrà subire una mutazione; se l’allele mutante però troverà le condizioni per diffondersi nella popolazione e superare la frequenza dell’1% non si parlerà più di mutazione ma di morfo.
Possono essere distinte in due categorie: mutazioni puntiformi e mutazioni per sequenze ripetute. Le prime sono causate da sostituzioni di basi o da inserzioni o delezioni di coppie di basi (mutazioni indel). La seconda categoria comprende le mutazioni causate sempre da inserzioni o delezioni ma di sequenze di basi ripetute.
Mutazioni puntiformi
Sostituzioni di basi: Determinano uno scambio di un nucleotide con un altro. Sono definite transizioni qualora vi è un scambio di una purina con altra purina (A ↔ G) o di una pirimidina con un’altra pirimidina (C ↔ T); oppure transversioni quando lo scambio è di una purina con un a pirimidina o viceversa (C/T ↔ A/G). In genere le transizioni sono più frequenti delle transversioni. Quando ci si riferisce a mutazioni di una sequenza che codifica per un determinato prodotto genico le sostituzioni potranno essere:
Mutazioni per sequenze ripetute
Analoghe alle mutazioni indel, interessano però più di un nucleotide adiacente; in particolare interessano gruppi nucleotidici che formano una sequenza la quale si ripete più volte di seguito. La mutazione, che si origina nel corso della replicazione del DNA, provoca una variazione nel numero di queste sequenze ripetute; il nuovo filamento di DNA potrà presentarne in eccesso o in difetto. Il fenomeno che causa la mutazione è detto slittamento della replicazione (replication slippage). Malattie genetiche associate a questo tipo di mutazione sono la Corea di Huntington e la sindrome dell’X fragile.
Effetti delle mutazioni geniche
Gli effetti possono essere notevolmente diversi a seconda del tipo di mutazione e della posizione in cui questa si verifica. Una mutazione può non portare a nessuna conseguenza e questo quando interessa DNA che non codifica (o meglio sembra non codificare) per nessun prodotto genico (il cosiddetto junk DNA o DNA spazzatura). Se la mutazione va invece ad alterare le sequenze codificanti, ovvero i geni, si ha una variazione nel tipo o nella quantità del corrispettivo prodotto genico, che può essere una proteina o RNA funzionale (rRNA, tRNA, snRNA ecc.). Parliamo in questo caso di mutazione biochimica; se la mutazione biochimica porta a una variazione visibile del fenotipo si parla di mutazione morfologica.
Inoltre distinguiamo, sempre in relazione agli effetti, in:
mutazione positiva: quella che porta un vantaggio evolutivo;
mutazione neutra: quella che non risulta in un depotenziamento della capacità riproduttiva dell’individuo;
mutazione subletale: quella che rende più difficoltosa la perpetuazione riproduttiva dell’individuo (il tipico esempio sono le malattie genetiche che debilitano in qualche modo l’individuo, rendendolo meno capace di riprodursi, senza però impedirglielo totalmente);
mutazione letale: quella che non permette all’individuo di raggiungere l’età riproduttiva o non gli permette di riprodursi.
L’efficacia della mutazione, sia positiva che negativa, dipende poi dal tipo di allele mutato così creato; questo potrà essere infatti dominante o recessivo. Nei diploidi (2n cromosomi) se è dominante avrà sempre effetto (sia in un eterozigote che in un omozigote dominante); se è recessivo, essendo aploinsufficiente, per avere effetto ha bisogno che anche l’altro elemento della coppia genica sia mutato (individuo omozigote recessivo). Negli aploidi , che sono emizigoti (n cromosomi), la mutazione avrà invece sempre effetto. (Fonte adattata e rielaborata: ftp://89-97-218-226.ip19.fastwebnet.it/web1/DNA/dna.htm)
Dal minuto 4.47 del video, un esempio di quotidiana mutazione genica:
La sintesi proteica
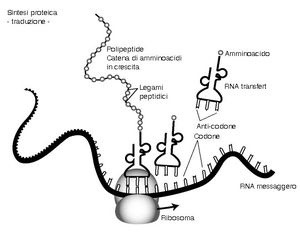
La traduzione è lo stadio della sintesi proteica in cui le istruzioni portate dall’m-RNA vengono tradotte nella sequenza corretta di amminoacidi per formare una proteina.
La traduzione ha luogo nel ribosoma (formato da r-RNA e proteine), composto da due subunità: quella piccola contiene un sito di legame per l’m-RNA; quella grande ha due siti di legame per due molecole di t-RNA e un sito che catalizza la formazione del legame peptidico tra due amminoacidi adiacenti.
Ogni molecola di t-RNA è specifica per un unico amminoacido ed è in grado di riconoscere sia l’amminoacido che deve trasportare, sia il codone complementare di m-RNA associato al ribosoma.
La traduzione ha inizio quando due codoni del filamento di m-RNA si legano alla subunità piccola di un ribosoma. Il primo codone è la tripletta di “inizio lettura” AUG, alla quale corrisponde l’amminoacido metionina; il secondo codifica il primo vero amminoacido della proteina. I due t-RNA, che hanno rispettivamente l’anticodone di inizio e l’anticodone complementare al secondo codone, si legano alla subunità grande e si forma un legame peptidico (cioè il legame tra amminoacidi che forma le proteine) tra i due amminoacidi trasportati.
Il t-RNA di inizio si stacca dal ribosoma mentre il dipeptide (i due amminoacidi uniti dal legame peptidico) rimane legato al secondo t-RNA. Il ribosoma si sposta sopra un altro codone dell’m-RNA e una nuova molecola di t-RNA con il proprio amminoacido si dispone nel sito di legame vuoto del ribosoma. Si crea un nuovo legame peptidico e il tripeptide si salda all’ultimo t-RNA. Il processo di allungamento della catena polipeptidica prosegue in questo modo finché tutte le triplette sono state tradotte e viene raggiunto il codone di “fine lettura”. La proteina completa si stacca dal ribosoma e specifici enzimi scindono il legame con la metionina.
Ecco inoltre un video esemplificativo dell’argomento trattato:
Il codice genetico

Come ben sappiamo ogni cromosoma é formato sia da proteine che da DNA. Ogni proteina contiene 20 amminoacidi differenti, ma il DNA e l’RNA, fonti del codice genetico delle proteine, contengono solo quattro basi azotate. Come é possibile?
Se ciascun nucleotide codificasse per un amminoacido, alle quattro basi corrisponderebbero solo quattro amminoacidi. Analogamente, se un amminoacido fosse codificato da due nucleotidi ci sarebbero al massimo 16 amminoacidi, comunque non sufficienti. Per ottenere un numero più che sufficiente di combinazioni, ogni amminoacido deve essere quindi codificato da tre nucleotidi, per un totale di 64 amminoacidi. Ogni combinazione é quindi costituita da una sequenza di tre nucleotidi chiamata codone.
Di queste 64 combinazioni, 3 rappresentano segnali di arresto (UUA, UAG e UGA) e le restanti 61 dei veri e propri amminoacidi, corrispondenti ai soli 20 presenti nella proteina. Ciò é possibile poiché i codoni ai quali corrisponde uno stesso amminoacido differiscono spesso solo per il terzo nucleotide ed é per questo che il codice viene definito degenerato.
La struttura del DNA e del RNA

Dal sito della DeAGOSTINI sapere.it, ecco un utile riassunto delle nozioni riguardante la struttura del DNA e del RNA.
